
计算机视觉是近几年来热门的AI研究领域之一,它的作用是让计算机能够理解和处理图像和视频数据,其研究方向包括目标检测与识别、图像分割、姿态估计、行为分析等;常用算法包括卷积神经网络(CNN)、支持向量机(SVM)、深度学习(如ResNet、YOLO)等。计算机视觉在许多领域都有广泛的应用,包括人脸识别、自动驾驶、安防监控、医学影像分析、工业检测和机器人视觉等。
在Computers, Materials & Continua(CMC)最新的76卷第1期中,刊登了多篇关于计算机视觉研究与应用的论文。我们精心筛选了7篇来自不同国家优秀学者的杰出论文,分享最新的计算机视觉方向的研究成果。
精选导读
01.Facial Expression Recognition Model Depending on Optimized Support Vector Machine
基于优化支持向量机的面部表情识别模型
Amel Ali Alhussan, Fatma M. Talaat, El-Sayed M. El-kenawy, Abdelaziz A. Abdelhamid, Abdelhameed Ibrahim, Doaa Sami Khafaga*, Mona Alnaggar
https://www.techscience.com/cmc/v76n1/53096/html
Figure 1: The proposed facial expression recognition model (FERM)
面部照片中可能包含多种面部表情,代表一种特定类型的情绪。将人脸照片转换成视觉词集,进行全局表情识别是可行和有用的。本文的主要贡献是提出了一种基于优化支持向量机的面部表情识别模型。为了测试所提出的模型(FERM)的性能,使用了AffectNet。AffectNet使用六种不同语言的1250个与情绪相关的关键字搜索三大搜索引擎,并在网上获得超过100万张面部照片。FERM由三个主要阶段组成:(i)数据准备阶段,(ii)应用网格搜索进行优化,(iii)分类阶段。使用线性判别分析(LDA)将数据分为八个标签(中性,快乐,悲伤,惊讶,恐惧,厌恶,愤怒和蔑视)。由于使用了LDA,支持向量机的分类性能得到了明显的提高。采用网格搜索方法寻找支持向量机的超参数(C和gamma)的最优值。优化后的SVM算法达到了99%的准确率和98%的F1分数。
02.Traffic Sign Detection with Low Complexity for Intelligent Vehicles Based on Hybrid Features
基于混合特征的低复杂度智能汽车交通标志检测
Sara Khalid, Jamal Hussain Shah*, Muhammad Sharif, Muhammad Rafiq, Gyu Sang Choi*
https://www.techscience.com/cmc/v76n1/53045/html
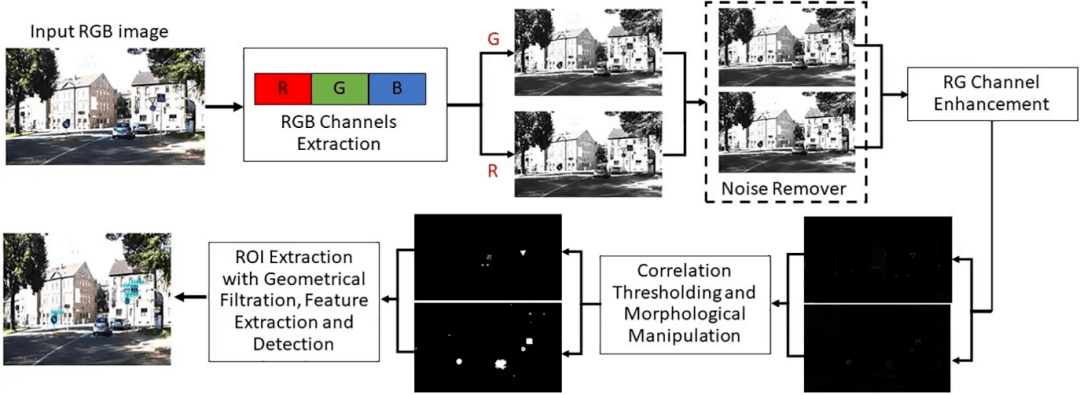
Figure 2: The proposed TSD approach
交通标志对于每个文明国家来说都是非常重要的,这使得研究人员更加关注交通标志的自动检测。由于处于黑暗、遥远、部分遮挡、受照明或类似物体的影响,检测这些交通标志具有挑战性。针对这些问题,提出了一种创新的彩色图像中红蓝交通标志检测方法。该技术旨在设计一种高效、稳健和准确的方法。为了实现这一点,最初,该方法提出了一个新的公式,受现有工作的启发,使用红色和绿色通道而不是蓝色通道来增强图像,该通道使用从图像的相关属性计算的阈值进行分割。其次,在现有特征的激励下,提出一组新的特征。在图像的Red, Green, and Blue (RGB), Hue, Saturation, and Value (HSV)和YCbCr颜色模型通道上提取纹理和颜色特征后进行融合。随后,将该特征集应用于不同的分类框架,其中二次支持向量机(SVM)以98.5%的准确率领先于其他分类框架。
03.Lightweight Surface Litter Detection Algorithm Based on Improved YOLOv5s
基于改进YOLOv5s的轻型表面垃圾检测算法
Zunliang Chen, Chengxu Huang, Lucheng Duan, Baohua Tan*
https://www.techscience.com/cmc/v76n1/53099/html

Figure 12: Comparison chart of model detection results. (a) original YOLOv5s test results (b) improved YOLOv5s detection results
针对传统人工清理水面垃圾成本高、效率低的问题,提出了一种基于改进YOLOv5s的轻型水面垃圾检测算法,为水面垃圾清理船实时检测水面垃圾提供核心技术支撑。该方法通过在轻量级网络GhostNet中引入深度可分离卷积GhostConv来代替原始YOLOv5s特征提取与融合网络中的普通卷积来减少网络参数;引入C3Ghost模块替代原有主干网络和颈部网络中的C3模块,进一步减少计算量。在骨干网中引入卷积块注意机制(CBAM)模块,增强网络从图像中提取重要目标特征的能力。最后,利用Focal-EIoU损失函数对损失函数进行优化,提高了收敛速度和模型精度。实验结果表明,改进后的算法在自制水面凋落物数据集的各个方面都优于原有的Yolov5s算法,并且在模型大小、检测精度和速度上都比目前的一些主流算法有一定的优势,可以解决现实生活中水面凋落物的实时检测问题。
04.Anomalous Situations Recognition in Surveillance Images Using Deep Learning
基于深度学习的监控图像异常情况识别
Qurat-ul-Ain Arshad, Mudassar Raza, Wazir Zada Khan, Ayesha Siddiqa, Abdul Muiz, Muhammad Attique Khan*, Usman Tariq, Taerang Kim, Jae-Hyuk Cha*
https://www.techscience.com/cmc/v76n1/53106/html

Figure 3: Images from suspicious activity dataset including five types of classes
通过视频异常检测,可以发现监控视频或图像中可能导致灾难、事故、犯罪、暴力、恐怖等安全问题的异常情况。然而,由于在火车站、繁忙的运动场、机场、购物区、军事基地、护理中心等复杂环境中人类活动的变化,将异常情况与正常情况区分开来可能具有挑战性。利用深度学习模型的学习能力,以更高的准确率识别异常情况。本文提出了一种称为异常情况识别网络(ASRNet)的深度学习架构,用于深度特征提取,以提高对各种异常图像情况的检测精度。拟议的框架有五个步骤。第一步,在CIFAR-100数据集上对所提出的体系结构进行预训练。第二步,利用可疑活动识别数据集,利用提出的预训练模型和Inception V3架构进行特征提取。第三步进行序列特征融合,第四步利用蜻蜓算法进行特征优化。最后,利用优化后的特征,利用各种支持向量机(SVM)和基于k -最近邻(KNN)的分类模型检测异常情况。通过将优化特征的数量从100个变化到1000个,在可疑活动数据集上验证了所提出的框架。结果表明,该方法能够有效地检测出异常情况,使用三次支持向量机的检测准确率达到99.24%。
05.Appearance Based Dynamic Hand Gesture Recognition Using 3D Separable Convolutional Neural Network
基于外观的三维可分离卷积神经网络动态手势识别
Muhammad Rizwan*, Sana Ul Haq*, Noor Gul, Muhammad Asif, Syed Muslim Shah, Tariqullah Jan, Naveed Ahmad
https://www.techscience.com/cmc/v76n1/53071/html
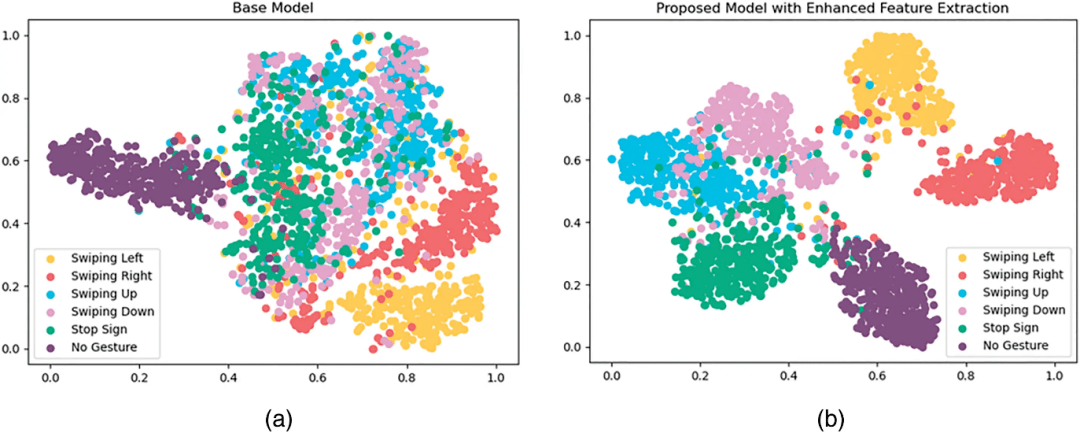
Figure 7: Visualization of the extracted features using t-SNE for the (a) base model, and (b) proposed model with enhanced feature extraction
基于外观的动态手势识别(HGR)是人机交互(HCI)领域的一个重要研究方向。许多环境和计算约束限制了它的实时部署。此外,随着拍摄对象与相机距离的增加,模型的性能也会下降。考虑到模型的计算复杂度和识别精度,本文提出了一种三维可分离卷积神经网络(CNN)。使用20BN-Jester数据集训练6个手势类的模型。在达到94.39%的最佳离线识别准确率后,该模型在考虑被摄主体的注意力、做出手势的瞬间以及被摄主体与相机的距离的情况下进行实时部署。尽管在许多研究文章中进行了讨论,但距离因素在实时部署中仍然没有得到解决,导致识别结果下降。
06.Vehicle Detection and Tracking in UAV Imagery via YOLOv3 and Kalman Filter
基于YOLOv3和卡尔曼滤波的无人机图像车辆检测与跟踪
Shuja Ali, Ahmad Jalal, Mohammed Hamad Alatiyyah, Khaled Alnowaiser, Jeongmin Park*
https://www.techscience.com/cmc/v76n1/53067/html

Figure 4: Road Extraction (a) original image, (b) segmented image
无人驾驶飞行器(uav)可用于监控各种设置中的交通,包括安全,交通监视和交通控制。由于面临的挑战和各种各样的应用,许多学者都被吸引到这个话题上。本文提出了一种基于道路提取和道路上目标识别的新型高效车辆检测与跟踪系统。它的灵感来自现有的检测系统,包括固定数据收集器,如感应回路和固定相机,具有有限的视野,不能移动。本研究的目标是开发一种首先提取感兴趣区域(ROI),然后发现和跟踪感兴趣项目的方法。建议的系统分为六个阶段。在第一阶段,从获得的数据集中获得的照片被适当地地理参考到它们的实际位置,之后它们都被共同注册。在第二阶段,使用GrabCut方法检索ROI或道路及其对象。第三阶段是数据准备。使用高斯模糊消除分割图像的噪声,然后将图像更改为灰度并转发到下一阶段进行额外的形态学处理。第四步使用YOLOv3算法查找照片中的汽车。然后利用卡尔曼滤波和质心跟踪对被检测车辆进行跟踪。然后使用Lucas-Kanade方法对飞行器进行轨迹分析。使用VAID (Vehicle Aerial Imaging from Drone)数据集对建议模型进行了测试和评估。在检测和跟踪方面,该模型的准确率分别达到96.7%和91.6%。
07.Ship Detection and Recognition Based on Improved YOLOv7
基于改进YOLOv7的船舶检测与识别
Wei Wu, Xiulai Li, Zhuhua Hu, Xiaozhang Liu*
https://www.techscience.com/cmc/v76n1/53112/html

Figure 6: Ships detection results by improved YOLOv7
本文提出了一种先进的YOLOv7模型,以解决船舶形状不规则、大小不一等船舶检测和识别任务中的挑战。改进模型将传统YOLOv7模型中使用的固定锚箱替换为根据数据集中船舶尺寸分布专门设计的一套更合适的锚箱。本文还介绍了一种新型的多尺度特征融合模块,该模块由路径聚合网络(PAN)模块组成,能够实现不同尺度船舶特征的高效捕获。此外,通过应用数据增强技术(包括随机旋转、缩放和裁剪)增强了数据预处理,从而增强了数据的多样性和鲁棒性。使用随机抽样平衡数据集中正样本和负样本的分布,确保更准确地表示现实世界的场景。综合实验结果表明,该方法在检测精度和鲁棒性方面明显优于现有的最先进方法,突出了改进的YOLOv7模型在海洋领域实际应用的潜力。
CMC期刊简介

主编
Ankit Agrawal 、Timon Rabczuk、Guoren Wang
CMC-Computers, Materials & Continua期刊是一本经过同行评审的开源性期刊,期刊发表计算机网络、人工智能、大数据管理、软件工程、多媒体、网络安全、物联网、材料基因组、集成材料科学、数据分析、建模以及现代功能和多功能材料的设计和制造工程等计算机学科和材料学学科领域的原创研究论文。新型高性能计算方法、大数据分析以及推动材料技术发展的人工智能尤其受欢迎。目前CMC期刊被收录在一些世界主要引文数据库里,如SCI, Scopus, EI Compendex, Google Scholar等等。
